PyTorch 2.0稳定版发布:性能进一步提升
编辑:系统下载之家官网 2023-03-20 来源于:网络
PyTorch 2.0稳定版已经正式发布了,和第一代的版本相比有了非常大的改进,对API的torch.compile进行了更好的优化,而且在进行代码编辑的时候,PyTorch 2.0稳定版也拥有更加快速的生成速度,让你体验到即时生成的快感。程序整体的性能也有非常大的提升。一起来看看关于PyTorch 2.0稳定版的详细介绍吧。

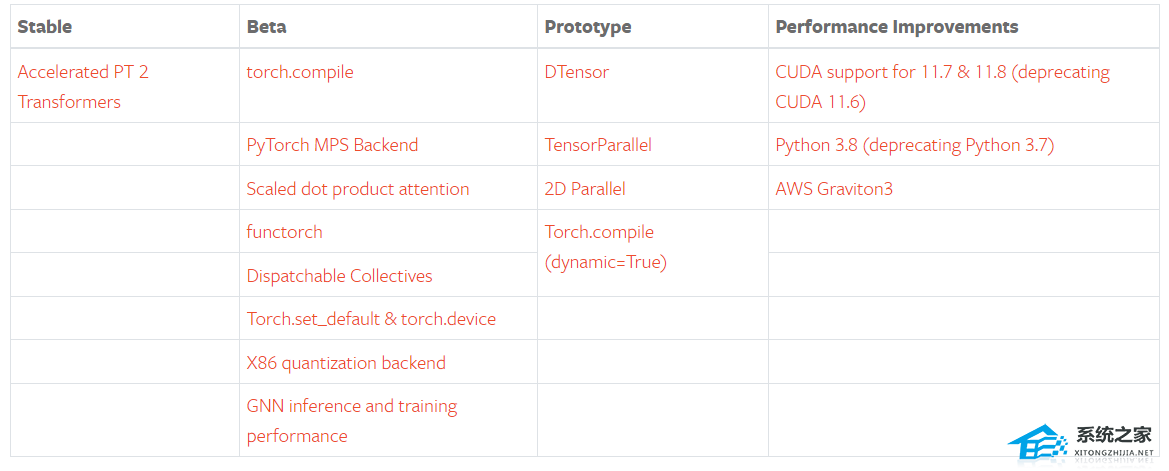
新版本更新之处包括稳定版的 Accelerated Transformers(以前称为 Better Transformers);Beta 版包括作为 PyTorch 2.0 主要 API 的 torch.compile、作为 torch.nn.functional 一部分的 scaled_dot_product_attention 函数、MPS 后端、torch.func 模块中的 functorch API;以及其他跨越各种推理、性能和训练优化功能的 GPU 和 CPU 的 Beta / Prototype 改进。
关于 torch.compile 的全面介绍和技术概况请见 2.0 入门页面。
除了 PyTorch 2.0,研发团队还发布了 PyTorch 域库的一系列 Beta 更新,包括 in-tree 的库和 TorchAudio、TorchVision、TorchText 等独立库。此外,TorchX 转向社区支持模式。
概括:
torch.compile 是 PyTorch 2.0 的主要 API,它能包装并返回编译后的模型。这个是一个完全附加(和可选)的功能,因此 PyTorch 2.0 根据定义是 100% 向后兼容的。
作为 torch.compile 的基础技术,TorchInductor 与 Nvidia / AMD GPU 将依赖于 OpenAI Triton 深度学习编译器来生成性能代码并隐藏低级硬件细节。OpenAI triton 生成的内核则实现了与手写内核和专用 cuda 库 (如 cublas) 相当的性能。
Accelerated Transformers 引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。API 与 torch.compile 集成,模型开发人员也可以通过调用新的 scaled_dot_product_attention 运算符直接使用缩放点积注意力内核。
Metal Performance Shaders (MPS) 后端能在 Mac 平台上提供 GPU 加速的 PyTorch 训练,并增加了对前 60 个最常用运算符的支持,覆盖 300 多个运算符。
Amazon AWS 优化了 AWS Graviton3 上的 PyTorch CPU 推理。与之前的版本相比,PyTorch 2.0 提高了 Graviton 的推理性能,包括针对 ResNet-50 和 BERT 的改进。
其他一些跨 TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 的新 prototype 功能和方法。
要查看公开的 2.0、1.13 和 1.12 功能完整列表,请点击此处。
稳定功能
PyTorch 2.0 版本包括 PyTorch Transformer API 新的高性能实现,以前称为「Better Transformer API」,现在更名为 「Accelerated PyTorch 2 Transformers」。
研发团队表示他们希望整个行业都能负担得起训练和部署 SOTA Transformer 模型的成本。新版本引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。
与「快速路径(fastpath)」架构类似,自定义内核完全集成到 PyTorch Transformer API 中 —— 因此,使用 Transformer 和 MultiHeadAttention API 将使用户能够:
明显地看到显著的速度提升;
支持更多用例,包括使用交叉注意力模型、Transformer 解码器,并且可以用于训练模型;
继续对固定和可变的序列长度 Transformer 编码器和自注意力用例使用 fastpath 推理。
为了充分利用不同的硬件模型和 Transformer 用例,PyTorch 2.0 支持多个 SDPA 自定义内核,自定义内核选择逻辑是为给定模型和硬件类型选择最高性能的内核。除了现有的 Transformer API 之外,模型开发人员还可以通过调用新的 scaled_dot_product_attention 运算来直接使用缩放点积注意力内核。
要使用您的模型,同时受益于 pt2 编译的额外加速 (用于推断或训练),请使用 model = torch.compile (model) 对模型进行预处理。
我们通过使用自定义内核和 torch.compile 的组合,使用 Accelerated PyTorch 2 transformer 实现了训练 transformer 模型的大幅加速,特别是大语言模型。
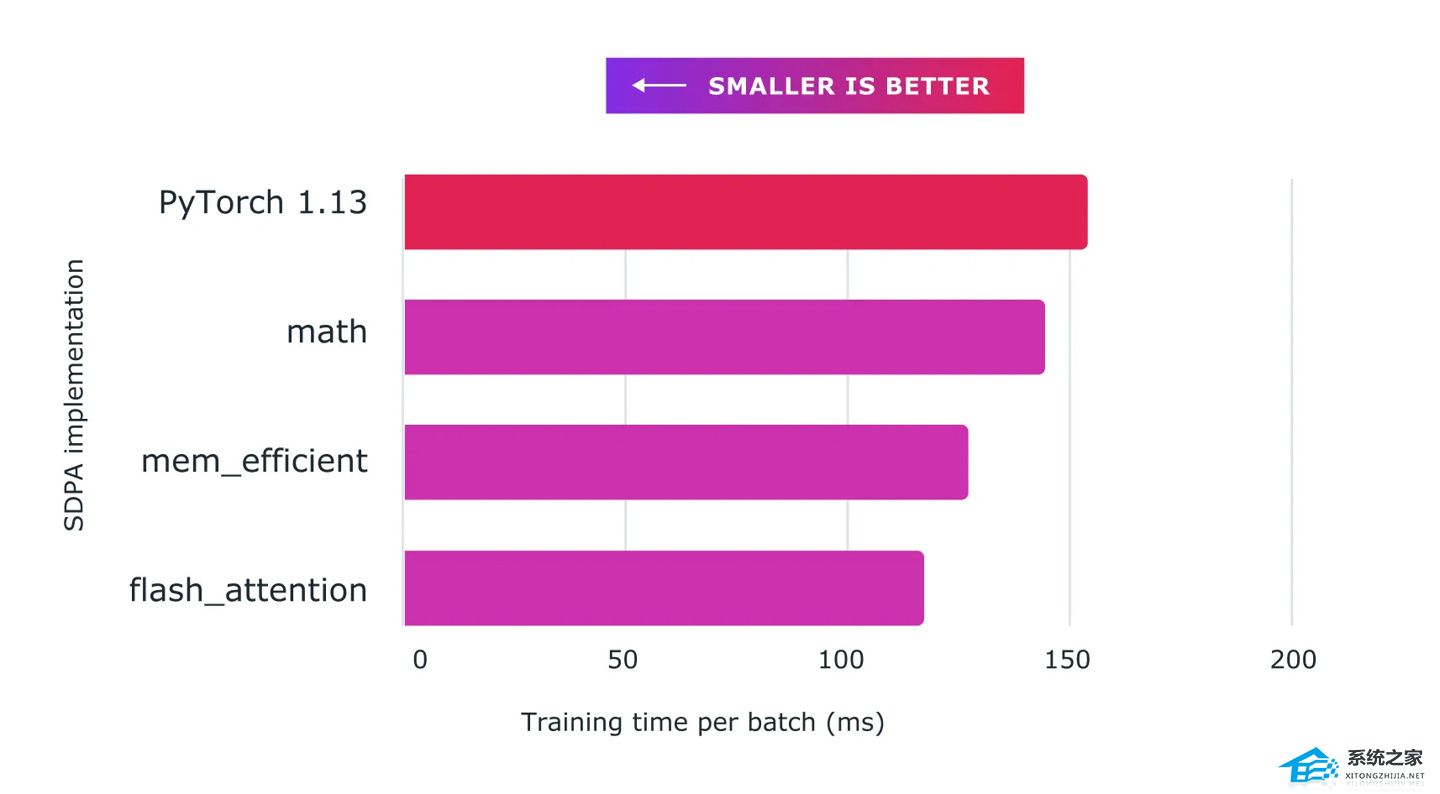
将缩放点积注意力与自定义内核和 torch.compile 结合使用可为训练大型语言模型(上图以 nanoGPT 为例)提供显著加速。
从官方数据可以看到,PyTorch 2.0 的编译效率比 1.0 实现了大幅提高。
这个数据来自 PyTorch 基金会在 Nvidia A100 GPU 上使用 PyTorch 2.0 对 163 个开源模型进行的基准测试,其中包括图像分类、目标检测、图像生成等任务,以及各种 NLP 任务。
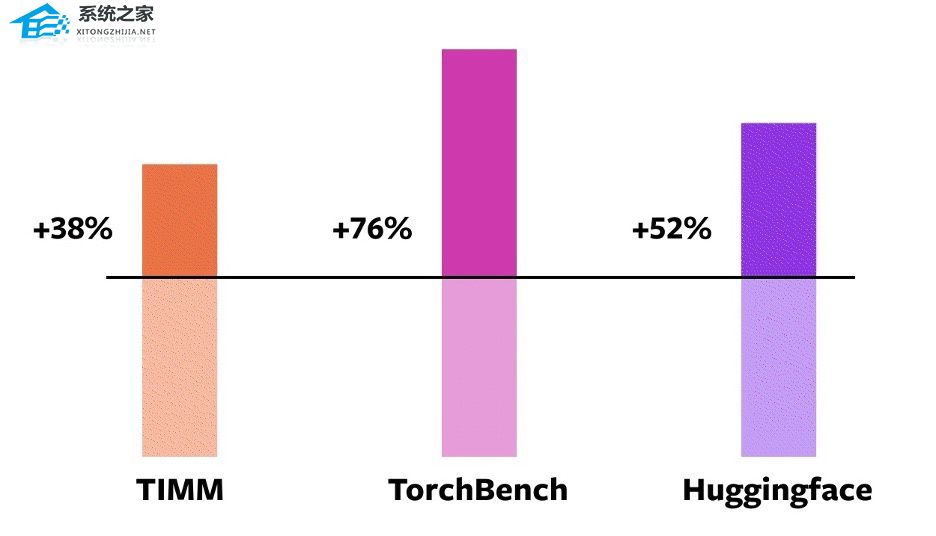
这些 Benchmark 分为三类:TIMM、TorchBench、HuggingFace Tranformers。
据 PyTorch 基金会称,新编译器在使用 Float32 精度模式时运行速度提高了 21%,在使用自动混合精度(AMP)模式时运行速度提高了 51%。在这 163 个模型中,torch.compile 可以在 93% 模型上正常运行。
值得一提的是,官方在桌面级 GPU(如 NVIDIA 3090)上测量到的加速能力低于服务器级 GPU(如 A100)。到目前为止,PyTorch 2.0 默认后端 TorchInductor 已经支持 CPU 和 NVIDIA Volta 和 Ampere GP,暂不支持其他 GPU、XPU 或旧的 NVIDIA GPU。
相关信息
-



-
-
2023/09/13 09:07
微软发布Win11 Beta 22621.2338/22631.2338(KB5030305) 九月更新! -
2023/09/13 09:03
微软发布Win11 21H2 KB5030217九月累积更新补丁!附完整的更新日志 -
2023/09/13 08:48
微软发布Win11 22H2 KB5030219九月累积更新补丁!更新“粘滞键”菜单中删除空白菜单项
-
-
 微软推送Win10九月更新KB5030211!解决了 Windows 操作系统的安全问题
微软推送Win10九月更新KB5030211!解决了 Windows 操作系统的安全问题系统之家9月13日最新消息,微软向Win10用户发布了九月最新星期二更新补丁KB5030211,版本号也提升为1904x.3448,此次更新也是主要解决了 Windows 操作系统的安全问题以及影响身份...
2023/09/13 08:35:58
-
 微软Win11 Build 23541 预览版暂时撤下开始菜单文件预览特性
微软Win11 Build 23541 预览版暂时撤下开始菜单文件预览特性系统之家消息,微软面向 Dev 频道的 Windows Insider 项目成员发布了 Win11 Build 23541 预览版更新,本次更新并未引入太大的变化,只是临时撤下了开始菜单的推荐区域文件预览。...
2023/09/11 09:40:41
热门资讯
- 1 Win10 21H1/20H2推送KB5001391升级:修复大量BUG!
- 2 系统之家官网 系统之家官网登录入口
- 3 显卡排行榜天梯图2022 显卡性能天梯图2022年7月版
- 4 安装KB5001391更新补丁后电脑绿屏怎么办?
- 5 Win11 22H2正式版发布时间确定了!将在9月20日推送更新!
- 6 微软扩展 Outlook 的邮件朗读功能:新增法语和西班牙语,通过聆听阅读邮件
- 7 Win11 22H2正式版发布了吗?Win11 22H2正式版什么时候发布?
- 8 微软新推出的KB5001391更新补丁,将带来怎样的效果呢?
- 9 iOS16.1描述文件下载 Apple iOS 16.1 Beta(20B5045d) 描述性文件下载
- 10 第三期鸿蒙OS系统内测申请入口!(附可申请机型)
频道热点资讯
- 1 Win10 21H1/20H2推送KB5001391升级:修复大量BUG!
- 2 系统之家官网 系统之家官网登录入口
- 3 安装KB5001391更新补丁后电脑绿屏怎么办?
- 4 Win11 22H2正式版发布时间确定了!将在9月20日推送更新!
- 5 微软扩展 Outlook 的邮件朗读功能:新增法语和西班牙语,通过聆听阅读邮件
- 6 Win11 22H2正式版发布了吗?Win11 22H2正式版什么时候发布?
- 7 微软新推出的KB5001391更新补丁,将带来怎样的效果呢?
- 8 微软Windows11系统用户上升至20%
- 9 微软新文档曝光:Windows 10视觉效果将迎来革新
- 10 Win10 21H1/20H2/2004/1909发布更新KB5003637下载地址合集!